
With a BA in math and an unfinished masters in Computer Science, I got a job in June 1982 at the Rocketdyne facility in Canoga Park, CA, helping to build the rocket engines that powered the American space shuttles.

(Above is my pic from the 1987 Rocketdyne open house. Wikipedia’s pic below is cleaner, and follows a remodel of the front of the building.)

This was the main Rocketdyne site, noted for the F-1 engine (like those that powered the Saturn V rockets that launched the Apollo missions) sitting prominently before the main entrance on Canoga Avenue.
Rocketdyne was then part of Rockwell International, itself derived from an earlier company called North American Aviation, which established the division in 1955. In the mid-1990s Rockwell sold the division (the Canoga site and four other sites) to Boeing. Boeing had no previous involvement in building rockets, though by the ‘90s Rocketdyne did considerably more than actual rocket work. (It designed and built the electrical power system for the International Space Station (ISS), for example.) Boeing kept Rocketdyne for about a decade, then sold it to Pratt & Whitney, known for making jet engines for aircraft, and itself a division of United Technologies. So throughout all of this, I worked for the same company for 30 years, despite the changes in corporate owners.
*
The job interview was bemusing. I had done a pre-interview with representatives from Rocketdyne and other companies at a job fair on the CSUN (California State University, Northridge) campus, where I was working my master’s degree, and was then invited by Rocketdyne for an on-site interview. I met a software manager named Ron S, who spent an hour trying to sell *me* on coming to work for him, never mind my trying to justify my qualifications; he spoke more than I did. (Perhaps all aerospace companies were in that mode, at the time; I also got offers from the only two other companies I did on-site interviews with: Hughes in El Segundo, and a provisional acceptance — “as soon as a position opens up” — from JPL in Pasadena.) Rocketdyne was obviously in a hiring mode, and in fact several others in my group started at about the same time, or just before or after: Bernie A, Sally F, Eulalia J, and Alan P a couple years later. (Alan and Bernie are still there!) (Pictures of these people on this page.)
My starting salary was $25,488/year. Despite being told, when I began work, that the only way to “get ahead,” i.e. to get promotions and salary increases, was to move around among different companies for the first few years, I never did that. I stayed with Rocketyne for over three decades, even as the corporate owners kept changing. In the early years I did very well, getting 8-10% raises every year (in addition to the regular adjustments for inflation, then very high, that everyone got), until leveling off after 5 or 7 years, then gradually creeping to just over 6 figures by 2012. I stayed a worker-bee; I never went into any kind of management. In the year after I was laid off, at the end of 2012, UTC sold Rocketdyne to Aerojet, a much smaller company based in Sacramento.
*

June 1982 was the very end of the keypunch age (I had been a keypunch operator at my college library job at CSUN) but not quite the age of the desktop computer terminal. My first desk, photo above, had no keyboard of any type. We did our work by filling in documents or coding sheets by hand, and then turn them over to a typist or keypunch operator for computer input. (We also used enormous FAX machines, the size of dishwashers.) The first computer terminal system we had was, IIRC, one designed strictly for word processing, called Wang. Using it entailed walking over a dedicated work station with a Wang terminal. Obviously you didn’t use it very often, because others needed their turns.
This desk photo was taken during a 1983 Rocketdyne Open House; more photos from that event on this page.
*

One aspect of the job that never went away was the requirement to fill out “time cards” to record, to the tenth of an hour, the work we’d done each day, divided among the various tasks each employee was authorized to charge. (This always amused my friends in other lines of work. “Really??”) This was because Rocketdyne, at least for the shuttle program, was a government contractor, and so had to report to NASA precisely how many hours had been worked each week to charge against the program’s cost-plus contract. When I began work, the time cards were the size of IBM computer punch cards, filled in by hand, and the cards were kept in bright red folders that had to be prominently visible on the employee’s desk, as in the desk photo above, for auditing purposes. In later years — by around 1997, judging from the task authorization sheet I have in my time card folder that I kept and took home with me in 2012, as in the photo here — everything went online.
As a salaried employee, I got paid a flat salary, a certain amount every paycheck, no matter how many hours I charged on my time card. A typical work week was 40 hours, of course, and there was rarely any reason to work more than 40 hours a week, though for management positions it was always assumed that the salary (increasingly generous the higher up in the management chain, of course) covered however many hours it took to do the job. Still, if for some reason anyone worked *more* than 40 hours a week, the hours over 40 were recorded on separate lines on the time card and considered unpaid “green time.” This was so the company could track how many hours everyone was working, and charge them to the customer, even the workers got paid only for 40 hours. In addition, tracking actual hours became increasingly important as, for CMM and process improvement purposes, actual hours it took to get the work done needed to be tracked rigorously.
There were if I recall a couple occasions when overtime was required — I’m thinking of the FMEA period following Challenger — and then we did get paid for that overtime, at a proportional hourly rate. But this was rare.
*

Over the decades, Wang gave way to a mainframe computer, a VAX, with terminals on everyone’s desks (as in the photo here), and eventually to Windows PCs connected to a network for file sharing, e-mail exchange, and eventually the internet. (There was an interim when both PCs and Macs came into use, depending on the task, until incompatibility issues forced a standardization, to PCs.) By the mid-1990s the Microsoft Office Suite was the standard toolset on every PC, including Word, Excel, PowerPoint, Access, and Outlook.
For about the first third of my career, I supported specific projects, first for Space Shuttle, then for ISS. For the second two thirds, I moved into process management and process improvement. Both activities were fascinating, in different ways, and interesting to summarize as basic principles.
SSME Controller
The project I was hired to work on was for SSME controller software maintenance. SSME is Space Shuttle Main Engine. Recall that the space shuttle was a hybrid vehicle. The plane-like shuttle had three rocket engines affixed to its rear end, and for launching it was attached to a large fuel tank to feed those three engines, plus two solid rocket boosters to give the vehicle sufficient initial boost to get into orbit. The boosters dropped away after a few minutes; the fuel tank stayed attached for the full 8 minutes that the SSMEs ran, before it too dropped away. By the time the shuttle returned from orbit and landed, only plane-like vehicle was left.
 The three engines, later called RS-25 engines, each had a “controller,” a microwave oven-sized computer strapped to its side, with all sorts of cables attached. The controller took commands from the outside, responded to them by adjusting fuel gauges to start, throttle, and shutdown the engine, and continuously (50 times a second) monitored temperature and pressure sensors for signs of any problem that might warrant emergency engine shutdown. (The photo here shows a controller on display at a Rocketdyne open house in 1987. More photos from that open house here.)
The three engines, later called RS-25 engines, each had a “controller,” a microwave oven-sized computer strapped to its side, with all sorts of cables attached. The controller took commands from the outside, responded to them by adjusting fuel gauges to start, throttle, and shutdown the engine, and continuously (50 times a second) monitored temperature and pressure sensors for signs of any problem that might warrant emergency engine shutdown. (The photo here shows a controller on display at a Rocketdyne open house in 1987. More photos from that open house here.)
The shuttle program had been under development since the 1970s. By the time I joined Rocketdyne in 1982, the first three orbital missions had flown, and the fourth would fly four days later. The controllers had been built and programmed originally by Honeywell, in Florida; once development was complete, maintenance of them was turned over to Rocketdyne, both in California and at a facility in Huntsville, AL.
It’s critical to appreciate how tiny these computers were, not in physical size but in capacity! The memory capacity was 16K words. It was thus extremely important to code as efficiently as possible. Yet while the code had been completed sufficiently for the early shuttles to fly, change orders from the customer (NASA) came in regularly, and (rarely) a bug might be found that required immediate repair. So there was work for a small team of software engineers, 10 or 12 of us, to process these changes and manage their deployment into periodic new versions of the software.
 You referred to the software by consulting print-outs kept in big blue binders. The “actual” software was stored on magnetic tapes. There was no “online” in those days.
You referred to the software by consulting print-outs kept in big blue binders. The “actual” software was stored on magnetic tapes. There was no “online” in those days.
Nor was the software “compiled.” The code was written in assembly language, with each word assigned a particular location in memory. There was a requirement for maintaining a certain proportion of unused memory. Some requirements or design changes entailed simply changing out some code words for others (e.g. the value of a fuel flow sensor qualification limit).
Other changes, to add functionality, required using some of that unused memory. But you didn’t rearrange the existing code to make room for the new. No, you “patched” the old code. You removed one word of old code and replaced it with a “jump” command (JMP) to an area of blank memory. You put new code there (beginning with the word you replaced with the jump), and ended with a “jump” command back to the old code at the place you jumped out from. This was because the software was only considered tested and verified in the fixed locations it was originally placed. To “move around” old code to fit in new code would require retesting and verifying all that moved around code. With patching, you only had to retest the one routine with the patch.
 The photo here shows the “test lab” onsite at Canoga where our team ran preliminary test verification of the patched software. (A controller box is visible at the back.) Official verification testing was done at the site in Huntsville AL.
The photo here shows the “test lab” onsite at Canoga where our team ran preliminary test verification of the patched software. (A controller box is visible at the back.) Official verification testing was done at the site in Huntsville AL.
At some point the controller itself was modified allowing for expanded memory and new version of controller software, “Block II,” written in C++, much easier to maintain, even if modified code, being compiled anew every time, required more testing. Still, some concerns remained, especially the limitation of memory space. Repeated patching of certain areas (sensor processing was an area continually refined by the experts at NASA) made the code less and less efficient. It became my specialty, of sorts, so tackle large redesign projects to improve that efficiency. The biggest one I did was that very module for sensor processing, which took some 25% of the total code and squeezed out 10% or 20% of its memory space.
My Experience of the Shuttle Program
Shuttle landings
The shuttle program had been underway, as I’ve said, for several years before I started my job supporting it. And while the shuttles launched from the opposite side of the country from southern California, they early ones landed relatively nearby, in the Mojave Desert on a dry lake bed at Edwards Air Force Base, a two hour drive north from LA. NASA made these landings open to the public. There had been a prototype shuttle, named Enterprise by popular demand, that was lifted into the air on top of a 747, and then dropped for practice landings at Edwards, several times before the first flight shuttle actually launched.
 Shuttle landings were always first thing in the morning, so to attend one you had to head out there the day before, and camp in the middle of huge dry lake bed. Two or three times some friends and I drove out to Edwards the afternoon before such a test flight, or (later) before an orbital flight was scheduled to land. The viewing area was a section of the enormous dry lake bed a couple miles away from the landing strip. (There were porta-potties but little else; you camped on the ground or in your car.) Here’s a page with more photos from one those landings.
Shuttle landings were always first thing in the morning, so to attend one you had to head out there the day before, and camp in the middle of huge dry lake bed. Two or three times some friends and I drove out to Edwards the afternoon before such a test flight, or (later) before an orbital flight was scheduled to land. The viewing area was a section of the enormous dry lake bed a couple miles away from the landing strip. (There were porta-potties but little else; you camped on the ground or in your car.) Here’s a page with more photos from one those landings.
Thousands gathered. Once the shuttle was spotted in the sky, a tiny dot, its descent and landing took all of five minutes. The landing was utterly silent — the shuttles were unpowered, and landed as gliders. You saw the plume of dust when the wheels hit the ground, and the roll-out of the lander as it coasted for a minute or so before it came to a stop. Everyone applauded.
And then everyone got back in their cars and took hours creeping out the two-lane road that led back to the interstate.
Test Stands
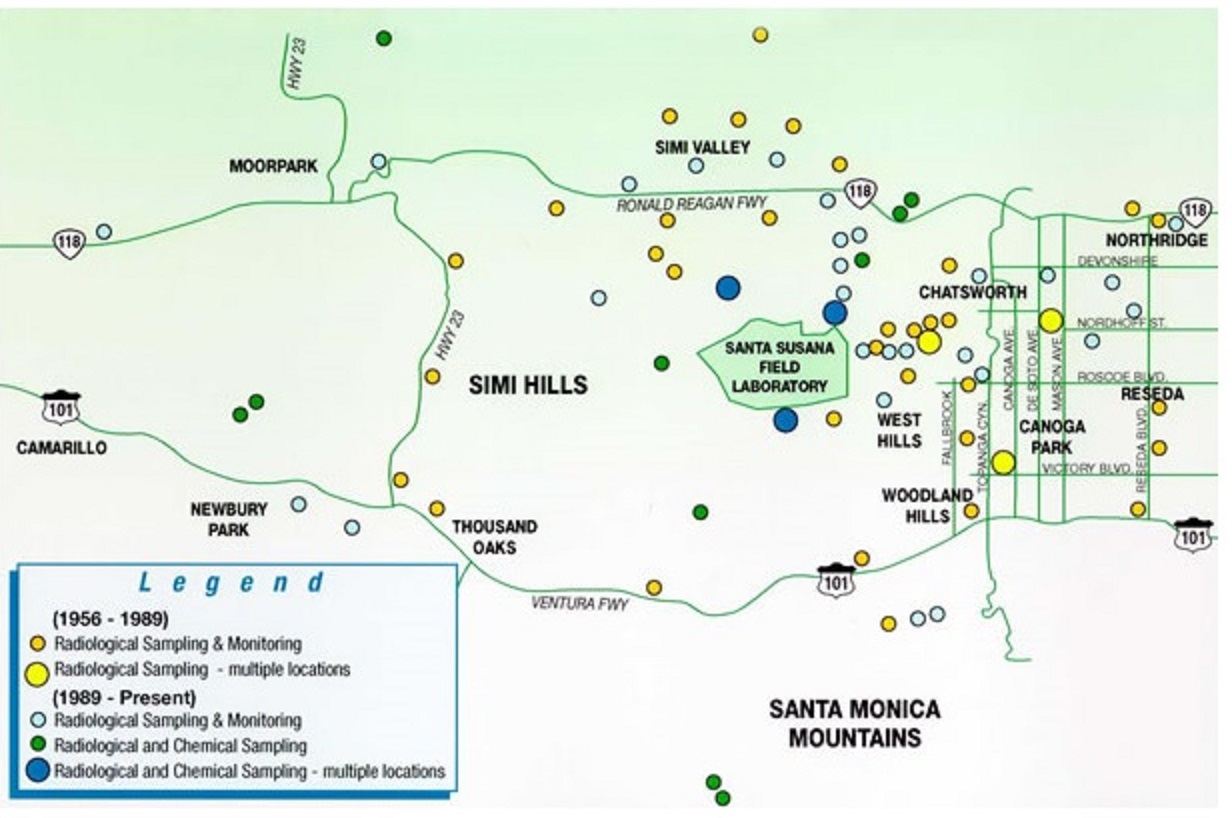
Perhaps my earliest exposure, beyond sitting at a desk revising code, to the bigger picture of the SSME program was a visit (with a group of other new employees) to the Santa Susana Field Lab (SSFL), in the mountains to the west of the Rocketdyne plant in Canoga Park, up in the SS mountains at the west end of the San Fernando Valley. (This rough map shows approximate locations.) The area had several large “test stands,” multi-story structures where an actual rocket engine could be mounted and fired. This LA Times article shows a photo of the test stand we visited, I think. The engine was mounted in the middle, and when fired its flaming exhaust would spew out, horizontally, from the big gap at the bottom. (Another pic here, showing the fiery plume of an engine test.)
The group of us stood in a bunker a few hundred feet away from the test stand (just left out of frame of the first pic above), behind walls of concrete. Still, it was very loud, and went on for several minutes.
I should note that the SSFL become controversial in later years, especially as the populated area of the San Fernando Valley expanded toward it. There were issues of ground contamination by chemicals use for the rocket tests, and even a nuclear event that had left some residue. The site had been built, of course, way back in the 1950s, long before residential areas encroached. It was completely shut down by the early 2000s.
Shuttle launches
I never saw a shuttle launch; the opportunity never arose. The launches were across the country, as I’ve said, at Kennedy Space Center in Florida. Rocketdyne did have a program for sending a couple employees to each launch, based on some kind of lottery or for meritorious service, but I never applied or was chosen.
The practical difficulties of attending launches were that the scheduled launches were often delayed due to weather, sometimes for days, so you couldn’t plan a single trip to last a couple nights; you’d have to extend your stay, or give up and come home.
On the Launch Pad
However, I did snag a trip to KSC, Kennedy Space Center, on my own time, a decade later, by which time I was no longer working on the program. The occasion was the 1992 World Science Fiction Convention, held that year in Orlando (just before Isaac Asimov died; the one and only time I ever saw him was at that con). A coworker from Rocketdyne in Canoga Park, Ken J, had moved back east and gotten a job at KSC, so I contacted him to see if he wanted to meet. He agreed and so I drove my rental car 90 miles from Orlando to KSC. He’d gotten me a pass and took me on a private tour.
Amazingly, the day I was there, the site was virtually empty. No tour groups, few employees. It’s as if we were granted some kind of special dispensation. We stepped briefly into the famous Mission Control room (empty), and then went up an elevator onto the actual launch pad where an actual space shuttle sat ready to launch, something most visitors, even authorized guests, never have a chance to see, I imagine. (This was 2 Sep 1992, so it was Endeavour, STS-47, on the pad.) We took the elevator to the base of the shuttle, with the three main engines to one side, and the tail of the shuttle was directly above us. (You can see where we would have stood in the opening shot of this video, https://www.youtube.com/watch?v=GREwspcOspM)
I could have reached up and touched the tail. I was told not to. I didn’t. And then we took the elevator up further, to the level of the beanie cap at the very top, then back down to the astronaut level where escape baskets awaited. Then went back down to earth, and took a short walk through of the enormous VAB, the Vehicle Assembly Building.
Years later I saw Endeavour again, after it was decommissioned and installed at the California Science Center, in Los Angeles, which we visited in 2013 — Blog Post.
SSME Business Trips
Analogous to the test stand visit described above, I and two other new employees were sent on an orientation trip to Stennis Space Center (SSC) in Mississippi, where another Rocketdyne facility oversaw test firings on much larger test stands than those at SSFL. On that trip, ironically, we didn’t see an actual engine test, but we did see the facility — a huge area out in the middle of the wilderness of the state, nor far across the border from New Orleans, where we’d flown in. Passing through New Orleans was a close to a glamorous business trip destination as I ever managed, at least while working SSME, and I only got a trip there that once.
(As I recall, the SSMEs, built in the factory at Canoga Park, were trucked across the country to Stennis, for final testing. Then they were put on a barge and sent to Florida, partly through the intracoastal waterway, to the Cape, where they were mounted on shuttles.)
Much more frequently the Controller team took trips to Huntsville, Alabama, to the NASA Marshall Space Flight Center, where yet another Rocketdyne facility held a software team that did the formal testing of the SSME Controller software. Sometimes we went to help oversee formal testing, or sometimes to take classes from the more senior staff there. There were no test firings there.
Vandenberg and Slick Six.
 I was able to attend a field trip for Rocketdyne employees to a new, under-construction, shuttle launch site at Vandenberg Air Force Base, on the coast northwest of Santa Barbara. This would have been mid- or late-1980s. The site was called Space Launch Complex 6, SLC-6 (https://en.wikipedia.org/wiki/Vandenberg_Space_Launch_Complex_6), pronounced “slick six.” It was planned to be a second site to launch space shuttles, in addition to Kennedy , but for various reasons was never completed. I recall this visit especially because I had my camera with me and took a bunch of photos (posted on this page). The occasion was the launch, mid-day, of satellite-carrying rocket. Then we got a tour of the construction site. And then got back on the bus to ride back to Canoga Park.
I was able to attend a field trip for Rocketdyne employees to a new, under-construction, shuttle launch site at Vandenberg Air Force Base, on the coast northwest of Santa Barbara. This would have been mid- or late-1980s. The site was called Space Launch Complex 6, SLC-6 (https://en.wikipedia.org/wiki/Vandenberg_Space_Launch_Complex_6), pronounced “slick six.” It was planned to be a second site to launch space shuttles, in addition to Kennedy , but for various reasons was never completed. I recall this visit especially because I had my camera with me and took a bunch of photos (posted on this page). The occasion was the launch, mid-day, of satellite-carrying rocket. Then we got a tour of the construction site. And then got back on the bus to ride back to Canoga Park.
Not directly related to work, but Vandenberg often launched rocket with satellites around sunset, and the rocket contrails were sometimes visible 150 miles away, in LA. A couple times I got good pictures of those contrails, and two of them are posted on this page.
Challenger.
The first space shuttle disaster (https://en.wikipedia.org/wiki/Space_Shuttle_Challenger_disaster) happened in January 1986; I’d been working at Rocketdyne for less than four years. It happened about 8:30 in the morning west coast time, and fortunately or unfortunately, I was at home sick with a cold, watching the launch on TV. No doubt everyone at work was watching it too, and I can only imagine the collective reaction of everyone there seeing the shuttle explode on live TV. (Though at the time there were a few moments, even minutes, of befuddlement on the part of witnesses and even Mission Control about precisely what had just happened. “Major malfunction” I believe was the earliest description.) People couldn’t believe it.
What followed was months of analysis and investigation to understand the cause of the explosion, before any other shuttle missions were allowed to launch. The cause turned out to be rubber O-rings sealing joints in the SRBs, solid rocket boosters, that had gone brittle in the chilly morning air, letting the burning fuel in the booster escape out through a crack, triggering an explosion of the fuel tank containing liquid oxygen and liquid hydrogen. The SRBs were built by Morton Thiokol, a firm in Utah; Rocketdyne was relieved to find itself innocent of any role in the disaster. But NASA was by nature risk-averse, and it became even more so after this disaster. So every contractor for every component of the shuttle assembly spent months doing what was called FMEA, Failure Mode and Effects Analysis (https://en.wikipedia.org/wiki/Failure_mode_and_effects_analysis), an intensive examination of every component looking for any possible, as-yet unanticipated failure scenario. In particular was the emphasis on single point failures, a catastrophe that would result if a single component, say a sensor, failed. (This kind of single-point failure of a sensor is what brought down two 737-MAX passenger jets in 2019.) The SSMEs were full of redundancies — two command busses, two or even four of each type of sensor, and much of the software function in our software was to constantly evaluate these sensor readings against qualification limits and then against each other, with various command responses should a sensor seem to have gone wrong. The FMEA at Rocketdyne involved overtime work, sometimes late in the evening after dinner, over many weeks.
Columbia.
The second space shuttle disaster (https://en.wikipedia.org/wiki/Space_Shuttle_Columbia_disaster) occurred in 2003, on the mission’s re-entry rather than take-off, and again I saw it from home on TV. It was a Saturday morning, and the catastrophe happened around 9am eastern, so had already happened by the time I turned on the TV news. I followed the investigation and resolution of the incident over the next months, but was no longer working on the shuttle program at that time and had no involvement with the investigation.
Space Station Support
By the early 1990s the Space Shuttle program had matured and required less and less maintenance. Meanwhile Rocketdyne had taken on another large NASA contract, building the electrical power distribution system for the International Space Station, ISS. At some point they needed extra help to complete the local testing of the software, and brought several of the SSMEC staff over to support this aspect of the program.
I had a much narrower involvement with this program, a more limited role. For the Controller software implementing a change typically involved modifying requirements, design, and code (but not test). For ISS I did two supporting roles involving test only, and now that I think of it, these occurred a couple three years apart.
First, my task was to convert a regularly updated set of Excel spreadsheets, containing records of various components and appropriate command responses, into a Microsoft Access Database that the testing team could more easily consult and analyze. This is how I learned Access, which I later parlayed into the building of Locus Online and my science fiction awards database, sfadb.com, beginning 1997.
Second was support of the program’s FQT (formal qualification testing), which entailed running test cases in its test lab, just as the SSME team had done years before for the Controller software. The schedule required near-round-the-clock use of the lab, which means that some of us, including me, would have to go into work in the evening after dinner for a couple hours to run the day’s allotment of test cases.
Process Improvement
Eventually I and two others, my coworker Alan P and our immediate manager Jere B, accepted a completely new assignment: process engineering and improvement. This was a corporate concern, not a customer one, and became important as Boeing acquired Rocketdyne from Rockwell.
This suited me because I was as fascinated by the processes of doing software, all the conceptual steps that go into creating a complex product for delivery to a customer, as much as the details of any particular program. With minor detours, process definition and improvement were the focus of my second and third decades of work at Rocketdyne.
To explain what process improvement means, it’s useful to begin by describing the basic software engineering process itself.
Software Engineering
Software engineering is, in a sense, the bureaucratic overhead of computer programming, without the negative connotation of bureaucracy. It’s the engineering discipline that includes the management structure, the coordination of individuals and teams, the development phases, and the controls that are necessary to get the customer’s desired computer program, software, into the target project and to be sure it works correctly and works as the customer intended.
At the core are several development phases. First of these is system requirements. These are statements by the customer (in these cases NASA) about what they want the software to do. These statements are general, in terms of the entire “system” (e.g., SSMEs, the Space Shuttle Main Engines), and not in software terms. An example might be, “the software will monitor the temperature sensors and invoke engine shutdown should three of the four sensors fail.” (And these might be very informal; for SSMEC, as little as a handwritten statement on a single-page form and handed to the Software Manager.)
The next phase is software requirements. This is where software engineers translate the system requirements into a set of very specific statements about what the software should do. The software requirement statements are numbered and typically use the word “shall” to indicate a testable requirement. An example might be: “The software shall, in each major cycle, compare the temp sensor to a set of qualification limits. If the sensor reading exceeds these limits for three major cycles, the sensor shall be disqualified. If three sensors become disqualified, the software shall invoke Emergency Shutdown.”
These requirements entail identifying the platform where the software where will run; the size of the memory; the specific inputs (sensor data, external commands) by name, and outputs (commands to the hardware, warnings to the astronauts) by name, and so on.
The next phase is design. Design is essentially everything that has to happen, given all the specific inputs, to produce the required outputs. The traditional method for documenting design was flowcharts (https://en.wikipedia.org/wiki/Flowchart), with various shapes of boxes to indicate steps, decisions, inputs, outputs, and so on.
 Next was code. When I began we were still writing code in assembly language! That was the language of the particular computer we were writing for, and consisted of various three-letter abbreviations for each command, where some commands were indications to move the flow of execution to some position above or below the current one. The photo here is a page of assembly language for the largest change I ever worked, a redesign of the entire sensor processing module; the entire code for the redesign fills this blue notebook. You can see columns for the physical location in memory, at far left; the letter-abbreviation for the computer instruction, down the middle; and comments that explain, almost line by line, what the code is doing, along the right.
Next was code. When I began we were still writing code in assembly language! That was the language of the particular computer we were writing for, and consisted of various three-letter abbreviations for each command, where some commands were indications to move the flow of execution to some position above or below the current one. The photo here is a page of assembly language for the largest change I ever worked, a redesign of the entire sensor processing module; the entire code for the redesign fills this blue notebook. You can see columns for the physical location in memory, at far left; the letter-abbreviation for the computer instruction, down the middle; and comments that explain, almost line by line, what the code is doing, along the right.
By the late ’90s the SSME team transitioned to a “Block II” controller, with software written in a higher level language, C++, that was much easier to write and maintain.
The final phase was test. The code was run in a lab where the target platform (the Controller box) was seated inside a hardware framework that simulated commands and sensor inputs to and from the Controller box. Each set of fake inputs was a test case, and each test case was designed to test and verify a particular item back in the software requirements.
The key all this was traceability. The software requirements were numbered; the design and then code documented at each step to indicate precisely which software requirement(s) they implemented. The test phase was conducted without knowledge of the design and code; the testers looked only at the requirements, and created test cases (ideally covering every possible combination of inputs and circumstances the software might have to respond to) to verify every single one.
This was the core sequence of developing software. There were two other attendant aspects.
One area was quality assurance, QA, and another configuration management, CM. QA people are charged with monitoring all the development phase steps and assuring that the steps for doing them are complete; they monitor the processes, essentially, without needing to know about the product being developed. CM folks keep track of all the versions of the outputs of each development phase, to make sure that consistency and correctness are maintained. You might not think this is a significant task, but as development continues, there are new versions of requirements, of design and code, of test procedures, all the time, and all these versions need to be kept track of and coordinated, especially when being released to the customer!
An attendant task of CM is, that after a release of the software to the customer, to keep track of changes to be made for the next deliverable version. Change requests can come in from anyone—the customer especially — for requirements changes, but also any software developer who spots an error or simply has an improvement suggestion (a clarification in the requirements; a simpler implementation in code) to make. And so there is an infrastructure of databases and CM folk to keep track of change requests, compile them for periodic reviews, record decisions on whether to implement each or not, and track them to conclusion and verification.
A supporting process to all these phases of software development was that of peer review, which became something of my specialty (I maintained the training course materials for the subject, and taught it a bunch of times, both onsite and at other sites). While these days “peer review” is tossed around as an issue of the credibility of scientific papers, our process had a very specific definition and implementation for software development. They key word is “peer”; it’s a review session not by management or QA or the customer, but by a software engineer’s peers.
First, the context is that there’s a team of software engineers all working changes to the same master product. When I started originally, working Block I, within a whole team of 10 or 12, one particular team member would work all phases of each particular change: changes to requirements, to design, to code, to test plans. Later, Block II was large enough to allow specific engineers to specialize in one of those phases; some would do only design work, some only test work. In either case, a change would be drafted as markups to existing documentation, and these markups were distributed to several other team members — “peers” — for review. After a couple days, a formal meeting would be held during which each reviewer would bring their comments, including errors found or suggestions for improvement. This meeting was conducted by someone other than the author of the changes. A member of the quality team attended, to assure the peer review process was followed correctly, but management was specifically not invited — the intent of the meeting was to get honest feedback without fear of reprisal.
As the meeting was conducted, it was not a presentation of the material; the reviewers were expected to have become familiar with it in advance of the meeting. And so the meeting consisted of paging through the changed documents. Anyone have comments on page 1? No? Page 4? (If no changes were made on pages 2 and 3.) OK, what is it, let’s discuss. And so on. The meeting participants would arrive at a consensus about whether each issue needed to be addressed by the change author. The number of such issues was recorded, the change author sent off to address them, with a follow-up after a week or so by the meeting coordinator, and QA, to assure all the issues were addressed.
We made a crucial distinction between what were called errors and defects. The worst news possible was an “external defect,” a flaw found by the customer in a delivered product. Such problems were tracked at the highest levels by NASA review boards. The whole point of peer reviews was to identify flaws as early as possible in the development process, so as to avoid external defects. Within the context of a peer review, a problem made by the change author, spotted by a peer reviewer so it could be fixed before the change products were forwarded to the next phase of development, was an “error.” A problem found from a previous phase of development, say a design error found during a code review, was a defect (an internal one, since caught before it reached the customer); such a defect meant that that an earlier peer review had not caught the problem.
Counts of errors and defects, per peer review and per product, were ruthlessly documented, and analyzed, at least in later years when process management and improvement took hold (more about that below). It was all about finding problems as early as possible in to avoid later rework, and expense.
This all may seem incredibly complex and perhaps overly-bureaucratic – but modern computer systems are complex, from the basic software in the Saturn V and the Space Shuttle, to the decades-later iPhones, whose functionality is likely a million times the Shuttle’s, depend on similar or analogous practices for developing software.
Aside: Coding
Every phase of the software development process can be done haphazardly, with poorly written requirements, design flowcharts with arrows going every which way and crossing over one another, spaghetti code with equivalent jumps from one statement to another, up or down the sequence of statements. Or, elegantly and precisely, with clean, exact wording for requirements (much as CMMI has continually refined; below), structured flowcharts, and structured, well-documented code. (With code always commented – i.e., inserted lines of textual explanation in between the code statements, delimited by special symbols so the compiler would not try to execute them, explaining what each group of code statements were intending to do. This would help the next guy who might not come along to revise the code for years; even if you’re that guy, years later.)
When problems occur with execution of the software, finding the spot to make a fix can be difficult, especially if the requirements are poorly written, and so on.
With code, more than the other phases, there is a certain utter certainty to its execution; however poorly or well it is written, it is deterministic. It’s digital, unlike the analog processes of virtually every other aspect of life, where problems can be attributed to the messiness of perception and analog sensory readings. So if there’s a problem, if running the code doesn’t produce the correct results, or if running it hangs in mid-execution, you can *always* trace the execution of one statement after the next all the way through the program, find the problem, and fix it. Always. (Except when you can’t, below.)
Even, or especially, when the problem isn’t in the code itself, but a consequence of poor design or ambiguous requirements. You can still find the spot where the code is doing something you didn’t mean it to do.
I keep this in mind especially since, outside industry work, I’ve done programming on my own, for my website and database projects, since the mid-1990s, at first writing Microsoft Word “macros” and then moving on to writing Microsoft Access “modules.” Both Locus Online (while I was running it) and my online Awards Indexes were built atop sets of MS Access databases containing tables of data and then sequences of macros and queries and code modules to process the data and generate text files that were uploaded to a server to become web pages.
With highly refined code used over and over for years (as in these databases), when running a step hangs in mid-execution, it is virtually always a problem with the data. The code expects a certain set of possible values; some field of data wasn’t set correctly, didn’t match the set of expected values; you find it and fix the data. But again, you always find the problem and fix it.
There’s a proviso, and an exception, to this thesis.
The proviso is that it can be very difficult to trace a problem, when running a piece of code hangs. Sophisticated compilers give error warnings, and will bring up and highlight the line of code where the program stopped. But these error warnings are rarely helpful, and are often misleading, even in the best software. The problem turns out to be one of data, or of a step that executed correctly upstream but produced incorrect results. And so you have to trace the path of execution and follow every piece of data used in the execution of the code. This can be difficult, and yet – it always gets figured out. (There are sophisticated debuggers that let you step through execution of code, line by line, and see how all the variables change, but I’ve never actually used one.)
Interrupts
The exception that I know of to this perfect deconstruction, likely one of a class of exceptions, is when the software is running in a live environment (real-time software) and is subject to interruptions based on new inputs (sensor, command), which can interrupt the regular execution of the software at any instant. My experience of this is from the Space Shuttle controller software, which ran at something like 50 times per second during the first few minutes of launch, while the main engines were running. If an astronaut abruptly hit an ‘abort’ button, say, or if another component of the shuttle blew up (as happened once), an ‘interrupt’ signal would be sent to the controller software to transfer regular execution to a special response module, usually to shut the engine down as quickly as possible. Whatever internal software settings that existed thus far might be erased, or not be erased but no longer be valid. These are unpredictable situations that might never be resolved. There is always an element of indeterminacy in real-time software.
Still, after the explosion of the Challenger in 1986, everyone worked overtime for months conducting an FMEA, Failure Mode and Effects Analysis, which for our software meant combing in fine detail to identify anywhere where an interrupt might cause catastrophic results. Fortunately, in that case, we never found one.
Data vs. Algorithm
One other comment about coding. This was especially important back in the SSME days when memory space was so limited, but it also still informs my current database development. Which is: the design/code implementation is a tradeoff, and interplay, between data and logic. When there is fixed data to draw upon, the way the data is structured (in arrays or tables, say) greatly affects the code steps that accesses it. You can save lots of code steps if you structure your sets of data appropriately at the start. Similarly, when I rebuilt the sensor processing module, writing a large section of the code from scratch, replacing earlier versions that had been “patched,” the savings in memory came partly from avoiding the overhead of patched software, but also from rebuilding data tables (of, for example, minimum and maximum qualification limits for sensors) in ways that made the writing of the code more efficient.
Advanced Techniques
The early Block I code was assembly language with no constraints; it was what was called spaghetti code, meaning that what with patching, the order of execution of instructions could jump up and down so that a line trace through the logic would cross over itself, again and again, like a plate of spaghetti. When I began in 1982 the software teams (led by the group in Huntsville AL) was just beginning to implement “structured” design and code, where arbitrary jumps were not allowed, and the flow of execution was usually downward, the exceptions being predictable loops. The flowcharts looked nicer, were much easier to understand, and easier to modify. Such “structured” code could be shown to correspond to actual statements of logic. Naturally, the old-timers resisted.
Later techniques included many of the basic ideas taught in any intro computer science course. Functions and subroutines; object-oriented programming. Still, given the risk-averse nature of NASA, when something worked, you didn’t overhaul it just to conform to some new-fangled academic standard. So it took some years for NASA and its contractors to adopt these better software techniques, as changes came along anyway and forced the software to be periodically rewritten.
These basic techniques are still used, of course; I write Visual Basic for the Microsoft App Macros, using functions and sub-routines as basic buildings blocks. But I have the impression that academic and industry techniques have left me far behind. My last taste of software maintenance, for NGPF around 2010 or so, involved graphic tools that automatically built the software based on diagrams you drew… No typing out of computer instructions.
Process Management and Improvement: CMMI
In the early 1990s NASA and the DoD adopted a newly developed standard for assessing potential software contractors. This standard was called the Capability Maturity Model, CMM, and it was developed by the Software Engineering Institute (SEI) at Carnegie Mellon University in Pittsburgh. The CMM was an attempt to capture, in abstract terms, the best practices of successful organizations in the past.
The context of the time was that software projects had a history of coming in late and over-budget. (Perhaps more so even than other kinds of engineering projects, like building bridges.) If there were root causes for that history, they may have been the tendency for the occasional software “genius” to do everything by himself, or at least take charge and tell everyone else what to do. The problem then would be what the team would do when this “hero” left, or retired. All that expertise existed only in his head, and went with him. Or there was a tendency to apply the methods of the previous project to a new project, no matter how different.
In any case, the CMM established a series of best practices for software development, arranged in five “maturity levels.” It was to be used primarily as a standard for external assessors to assess a company for consideration when applying for government contracts, and also as a guide for companies to manage their owns processes and projects in order to better compete in the industry.
The five levels apply to any kind of process, where the management of the process ranges from the simple and intuitive, to sophisticated and disciplined.
- Level 1, Initial, is the default, where projects are managed from experience and by intuition.
- Level 2, Managed, requires that each project’s processes be documented and followed.
- Level 3, Defined, requires that the organization have a single set of standard processes that are in turn adapted for each new project’s use (rather than each project creating new processes from scratch, or using whatever processes the customer likes).
- Level 4, Quantitatively Managed, requires that each project, and the organization as a whole, collect data on process performance and use it to manage the projects. (Trivial example: keep track of how many widgets are finished each month and thereby estimate when they will all be done.)
- Level 5, Optimizing, requires that the process performance data be analyzed and used to steadily implement process improvements.
Boiled even further down: processes are documented and reliably followed; data is collected on how the processes are executed, and then used to improve them, steadily, forever.
Examples of “improvements” might be the addition of a checklist for peer reviews, to reduce the number of errors and defects, or the acquisition of a new software tool to automate what had been a manual procedure. They are almost always incremental, not revolutionary.
The directions of those improvements can change, depending on changing business goals. For example, for products like the space shuttle, aerospace companies like Rocketdyne placed the highest premium on quality — there must be no defects that might cause a launch to fail, because astronaut’s lives are at stake. But software for an expendable booster might relax this priority in favor of, say, project completion time.
And software companies with different kinds of products, like Apple and Microsoft, place higher premiums on time-to-market and customer appeal, which is why initial releases of their products are often buggy, and don’t get fixed until a version or three later. But both domains could, in principle, use the same framework for process management and improvement.
Again, projects are run by processes, and in principle all the people executing those processes are interchangeable and replaceable. That’s not to say especially brilliant engineers don’t have a chance to perform, but it has to be done in a context in which their work can be taken over by others if necessary.
So…. In the early 1990s, while Rocketdyne was still part of Rockwell International, Rocketdyne and the several other divisions of Rockwell in southern California formed a consortium of sorts, which we called the “Software Center of Excellence” (SCOE, pronounced Skoe-ee) for the group effort of writing a set of standard processes that would satisfy the CMM, at least through Level 3. If I recall correctly, NASA had given its contractors a deadline for demonstrating compliance to Level 3, a deadline that was a few years out.
Rockwell set its own deadline: “Level 3 in ’93.” Ironically, it was exactly the kind of arbitrary goal that CMM warned against. We didn’t make it of course. A lesson of CMM was that you set goals based on measured capability, not external edicts.
So three of us at the Canoga site, me, Alan P, and Jere B, became Rocketdyne’s “software process improvement group” (SEPG). The work of writing 15 or 20 standard processes was divvied up among the various Rockwell divisions, and in a year or two we put out a “Software Process Manual” in 1994.
The task of writing “standard processes” was pretty vague at first. What is a process? What do you base it on? At its most basic, a “process” identifies a set of inputs (e.g. sensor readings, commands from the astronauts), performs a series of steps on them, and results in some number of outputs (e.g. commands to the engine to start, to throttle up, to throttle down, to shut down). But how do you write up a standard process for your organization about, say, configuration management? What elements of CM (e.g. version management, audits, etc.) were required to be included? The task was to combine the generalizations of the CMM with the reality of how the different divisions of Rockwell actually did such work, and try to integrate them into some general whole.
One perk of this era, in the early/mid 1990s, was that meetings among representatives from these various sites were held. The other sites were in Downey, Seal Beach, El Segundo, and Anaheim. At the time, Rockwell owned company helicopters! They were used to fly senior management back and forth among these sites, but if they were otherwise not reserved, lowly software engineers like Alan and me could book them, and get a half hour flight from Canoga Park to Downey, some 40 miles, avoiding an hour and half drive on the freeways. It was cool: the helicopter would land in a corner of the parking lot at the Canoga facility, we would walk toward it, ducking our heads under the spinning helicopter blades, and get a fantastic ride. What I remember especially is how the populated hills between the San Fernando Valley and west LA, crossing over the Encino Hills and Bel Air, were immense – nearly as wide as the entire San Fernando Valley. All those properties, so many with pools.
We didn’t always use the copters; I remember having to drive to the Seal Beach facility once, (a 55 mile trip) because as I got on the 405 freeway to drive home, the freeway was so empty – because of some accident behind where I’d entered – my speed crept up and I was pulled over, and got my first ever traffic ticket.
One other copter trip was memorable. Coming back from Downey, the weather was bad and the copter was forced to land at LAX. To approach LAX, a major airport with big planes landing and taking off, always from the east and west respectively, the copter would fly at a rather high altitude toward the airport from the south, and then spiral down to its target, a rooftop on a building in El Segundo on the south side of the airport. On that occasion we had to take a taxi back to the San Fernando Valley, as the rain came in.
The software CMM was successful from both the government’s and industry’s points of view, in the sense that its basic structure made sense in so many other domains. And so CMMs were written for other specific contexts: systems engineering; acquisitions (about contractors and tool acquisitions), and others. After some years the wise folks at Carnegie Mellon abstracted even further and consolidated all these models into an integrated CMM: CMMI (https://en.wikipedia.org/wiki/Capability_Maturity_Model_Integration). And so my company’s goals became satisfying this model.
The idea of conforming to the CMMI, for our customer NASA, entailed periodic “assessments,” where independent auditors would visit our site for some 3 or 5 days in order to assess the extent our organization met the standards of the CMMI. The assessment included both a close examination of our documented standard processes, and interviews with the various software managers and software engineers to see if they could “speak” the processes they used, day to day. Assessments were required every 3 years.
Rocketdyne’s acquisition by Boeing, in 1996, did not change the assessment requirements by our customer, NASA. Boeing supported the CMMI model. In fact it established a goal of “Level 5 by 2005” (far enough out to be plausible). The advance from Level 3 to Level 5 was problematic for many engineering areas: the collecting and analyzing of data for Levels 4 and 5 was seen as an expensive overhead that might not actually pay off. Rocketdyne, under Boeing, managed to do that anyway, using a few very selected cases of projects that had used data to improve a couple specific processes. And so we achieved Level 5 ahead of schedule, in 2004. (In fact, I blogged about it at the time: http://www.markrkelly.com/Views/?p=130.)
Time went on, and the SEI kept refining and improving the CMMI, both the model and the assessment criteria; Rocketdyne’s later CMMI assessments would not get by on the bare bones examples for Level 5 that we used in 2004. I’ve been impressed by the revisions of the CMMI over the years: a version 1.1, then 1.2, then 1.3, each time refining terminology and examples and sometimes revising complete process areas, merging some and eliminating others. They did this, of course, by inviting feedback from the entire affected industry, and holding colloquia to discuss potential changes. The resulting models were written in straightforward language as precise as any legal document but without the obfuscation. This process of steadily refining and revising the model is analogous to science at its best: all conclusions are provisional and subject to refinement based on evidence. (A long-awaited version 2.0 of CMMI has apparently been released in the past year, but I haven’t seen it.)
My involvement with this, at Rocketdyne, mirrored my earlier ambitions to rewrite blocks of patched code more efficiently. My final achievements, just before I was laid off and then finished when I came back as a contractor, was to rewrite some of the company’s patched process documents cleanly and efficiently. I thought I did a good job. But I have no idea what’s happened to those documents over the past decade since I left.
CMMI Highlights
- Business trips: There were lots of reasons for business trips in these years, and the trips were more interesting because they were to many more interesting places than Huntsville or Stennis. A key element of CMMI is training, the idea that all managers and team members are trained in the (company or project) processes they are using. At a meta-level, this included people doing process management taking courses in the CMMI itself, and in subjects like process definition (the various ways to capture and document a process). Such CMMI training was often held in Pittsburgh, at the SEI facility near CMU, but in later years I also recall trips to both Arlington and Alexandria, just outside Washington DC. And a couple such trips to San Diego. Alas, aside from dinners in the evening there was no time for sight-seeing.
- Conferences. Other trips were to attend professional conferences. Since dozens or hundreds of corporations across the country were using CMMI to improve their processes, or using the model to assess their performance, these conferences were occasions for these companies to exchange information and experience (sometimes guardedly). Much like a science fiction convention, there were speakers talking to large audiences, and groups of panelists speaking and taking questions from the audience; a few dozen presenters and hundreds or thousands of attendees. Furthermore these conferences were not tied to any particular city, and so (like science fiction conventions) moved around: I attended conferences in Salt Lake City (about three times), Denver, Pittsburgh, Tampa, and San Jose, and I’m probably forgetting some others.
- Assessments. Then there were the occasional trips to other Rockwell or Boeing sites, for us from Rocketdyne to consult with the process people there, or even to perform informal assessments of their sites (since Rocketdyne was relatively ahead of the curve). I did two such trips by myself, one in Cleveland, once in some small town (name forgotten) northeast of Atlanta.
- Maui. But the best assessment trip was one Alan P and I did in 1999, in Maui. The reason was that Rocketdyne (via some connection with manager Mike B) had a contract to maintain the software for some of the super-secret spy telescopes on top of Haleakala (https://en.wikipedia.org/wiki/Haleakala_Observatory). We didn’t have to know anything specific about the telescopes in order to assess the processes of the support staff, who worked in an ordinary office building down near the coast in Kihei. Our connection was that a manager, Mike B, who’d worked at Rocketdyne in California. had moved to Maui to head the facility there, and thought of us when needing an informal assessment. So Alan (and his wife) and I flew in early on a Saturday to have most of a weekend to ourselves, before meeting the local staff in their offices for the rest of the week. Meanwhile, we did get a tour of the observatory, if only a partial one, one evening after dinner, taking a long drive up the mountain and back in the dark. (The one hint I got about the secret scopes was that one of them was capable of tracking foreign satellites overhead, as they crossed the sky in 10 or 15 minutes, during daylight.)
- HTML. In the mid-1990s the world wide web was becoming a thing, and one application of web technology was for companies to build internal websites, for display of information, email, and access to online documents. (Eventually, everything was online and no one printed out documents, especially big ones like our process manuals.) With more foresight, I think, then I’d had when learning Access for ISS support, I volunteered to learn HTML and set up webpages for our process organization, the SEPG (Software Engineering Process Group). I did so over the course of a few months, and shortly I parlayed those skills into my side-career, working for Locus magazine — I volunteered to set up its webpage. Charles Brown had thought ahead to secure the locusmag.com domain name (presumably locus.com was already taken) for email purposes, but hadn’t found anyone to set up a site. So he took me up on my offer. The rest is history, as I recounted in 2017 here: http://locusmag.com/20Years/.
Moving Around

Rocketdyne consisted of a central site at 6633 Canoga Avenue in Canoga Park, a second site at De Soto and Nordhoff at the edge of Chatsworth, that Santa Susanna facility I discussed above, and sites in Huntsville AL and Stennis MI. The original Canoga site, seen in this vintage photo on the Wikipedia page, from the north, shows it back in the 1950s when there was almost nothing else around. The main building and factory, with some kind of fins on the top, is at upper right; this side of it are three office buildings.
As the years went by, as programs expanded or ended, as the staff waxed and waned, people were relocated among the various buildings and sites. I began at the far corner of the main building, moved for a while to the lower left building, Building 004, then by the early ’90s, when CMM began, to a leased building on Plummer street. This was where our initial Software Engineering Process Group (SEPG) staff was located when the 1994 Northridge earthquake hit. In the aftermath, we were given hardhats and allowed to enter the building only for an hour to two to gather up our stuff into boxes. [I have pics, insert here].
Later, the company leased a couple floors of one building in a quite beautiful industrial park at Fallbrook and Roscoe; this is where we were when we achieved CMMI Level 5.
And for the last decade or so of my career the software group was at the DeSoto site, first one building then another, then another. Always in cubicles. (Only managers had offices with doors.)
By 2010 or so, in fact, the original main site on Canoga was being shut down. The Space Shuttle era was over, and new programs required new manufacturing facilities that were constructed at DeSoto. Also, the Canoga site, at the corner of the upscale Warner Center, built in the ’80s and ’90s with high-rises and office parks, was much more valuable property than the DeSoto site. Ironically, therefore, though the Canoga site was razed somewhere around 2014, it remains empty to this day. (Perhaps a big development project delayed by the pandemic..?)
Reflections
Looking back at these engineering activities (as I draft this piece in 2020), it now occurs to me there’s a strong correlation between them and both science and critical thinking. When beginning a new engineering project, you use the best possible practices available, the result of years of refinement and practice. You don’t rely on the guy who led the last project because you trust him, or he’s a good guy. The processes are independent of the individuals using them; there is no dependence on “heroes” or “authorities.” There is no deference to ancient wisdom, there is no avoiding conclusions because someone’s feelings might be hurt or their vanity offended. Things never go perfectly, but you evaluate your progress and adjust your methods and conclusions as you go. That’s engineering, and that’s also science.
Things never go perfectly… because you can’t predict the future, and because engineers are still human. Even with the best management estimates and tracking of progress, it’s rare for any large project to finish on-time and on-schedule. But you do the best you can, and you try to do it better than your competitors. This is a core reason why most conspiracy theories are bunk: for them to have been happened, everything would have had to have been planned and executed perfectly, and without any of the many people involved leaking the scheme. Such perfection never happens in the real world.
UTC, P&W, ACE
For whatever reason, after a decade Boeing decided that Rocketdyne was not a good fit for its long-term business plans, and sold the division to Pratt & Whitney, an east coast manufacturer of passenger jet engines. Pratt & Whitney was in turn owned by United Technologies Corporation, UTC, whose other companies include Otis Elevators. While Boeing, a relatively laid-back West Coast company, had worked to assimilate our common processes via “Horizontal Integration Leadership Teams,” UTC, an east-coast company, was relatively uptight and authoritarian in simply imposing their processes on us. (Just as CMMI advises companies not to do.) This was visible no more starkly than with its “operating system,” a company wide set of tools and standards called ACE, for “Achieving Competitive Excellence.” ACE was homegrown by UTC and stood independent of industry or government standards. Furthermore, it was optimized for high-volume manufacturing, and was designed for implementation on factory floors. That didn’t stop UTC from imposing the totality of ACE on our very low-volume manufacturing site (one or two rocket engines a year) where most employees sat in cubicles and worked on PCs.
It’s notable too that while all sorts of information can be found on CMMI through Google searching, almost no details of ACE can be found that way; it’s UTC proprietary. I did finally find a PDF presentation (https://pdf4pro.com/view/acts-system-management-ace-caa-gov-tw-2c4364.html) that lists (on slide 7) the 12 ACE “tools,” from which I will describe just a couple examples. Most notorious was what P&W called “6S,” its version of UTC’s “5S,” which was all about workplace cleanliness and organization. The five Ss were Sort, Straighten, Shine, Standardize, and Sustain; the sixth one was, ungrammatically, Safety. While it may make sense to keep a manufacturing environment spic and span clean, when applied to cubicle work-places it became an obsession about tying up and hiding any visible computer cables, keeping the literal desktop as empty as possible, and so on. Many engineers resented it.
Another example was that in the problem-solving “DIVE” process, each ACE “cell” (roughly, each business area at a site) was obliged to collect “turnbacks,” which were any examples of inefficiency or rework. It didn’t matter to the ACE folks that in software we had a highly mature process for identifying “errors” and “defects”; we were required to double-book these for ACE as “turnbacks.” Furthermore, each cell was required to find a certain number of turnbacks each month, and show progress in addressing them. You can see how this would encourage a certain amount of make-work.
To avoid duplicate work, at least, I and others who maintained the software processes spent some time trying to resolve double-booking issues, even introducing ACE terminology into the processes we maintained to satisfy CMMI. (P&W didn’t care about CMMI, but our customers still did.)
So these last few years at Rocketdyne were my least pleasant. They ended on a further sour note as I was pulled away from process management and put onto a P&W project based back east that needed more workers, even remote ones. This was NGPF, for “next generation product family,” that became the PW1000G (https://en.wikipedia.org/wiki/Pratt_%26_Whitney_PW1000G), a geared turbofan jet engine for medium-sized passenger jets. A couple dozen of us at Rocketdyne were assigned to NGPF, but I was pulled in later than the initial group and got virtually no training in the computer-based design tools they used or background in the concept of the product. So my assignments were relatively menial, and frustrating because I had to figure things out as I went along, without proper peer reviews or the other processes we used for CMMI-compliant software projects.
There was one bright spot in these last years — I got my stepson Michael W a contact number at Rocketdyne to apply for a summer internship. I had nothing to do with the interview or application beyond getting the contact number. He got the job, not one but two summers in a row — in 2012, just before my layoff, and in 2013, when I was back there contracting. Michael could have gotten a full-time job there, but he found a position at The Aerospace Company in El Segundo, instead, and has been there ever since.
Layoff
NFPG was winding down, I had gone back to working a final pass on a new set of process documents, when a bunch of us were laid off in November 2012.
There had been waves of layoffs, every six months or, over the previous couple years. The reason, so far as I understood, was simply that NASA work was winding down, and there simply wasn’t enough such work to keep Rocketdyne as busy as it had been for the previous four or five decades. I had thought I was safe from layoff, because my expertise in process improvement and CMMI was unique in the company, excepting only my immediate managers. But, no. Mid-morning, I was called into the manager’s office (not Alan P’s, but his manager’s) and told my services were no longer needed. I was given 20 minutes or so to clean out my cubicle of personal items; books and large objects would be shipped to me later. Then, carrying a box of personal items, I handed in my badge and was walked out to my car.
The instructions then were to drive over to a hotel on Topanga Canyon Boulevard where several HR (human resources) people were waiting to out-brief that day’s layoffs (a couple dozen). They explained about severance payments and how they were calculated (one week’s pay for each year of work) and how to find out if you were eligible for a pension. I was slightly panicked; not expecting to retire for years, I had paid no attention to such matters.
Things worked out relatively well. Since I’d worked for the same company (however many corporate owners there had been, it was the same company for HR purposes) for 30 ½ years, and was old enough to have been grandfathered in to pension eligibility from Boeing. So I got a nice severance pay-out, and a pension beginning the following February, since the official layoff date was end of January 2013. I suspected, but never confirmed, that my name had been on the potential layoff list for some time, but management did me the courtesy of waiting until I was eligible for a full pension before selecting it. Six months earlier, I would not have not been eligible for the pension.
So I went home, and sat wondering what to do.
And one of the first things my partner and I did was to become “registered domestic partners” with the State of California, so he could cover me under his company’s medical plan. (This was before Obergefell.)
Contracting
But that wasn’t the end of my work for Rocketdyne.
I’d thought my job role was critical; if not, they must have someone to take it over, right? As it turned out, no. My work went undone, for months. Then in July 2013, realizing that work had to get done eventually (in order to maintain the site’s CMMI certification), they called me up on the phone. How about coming back to work, part-time, as a contractor?
Sure! Why not.
Technically, I went to work for a glorified temp agency, Pro Unlimited, that does “contingent workforce management.” Everything was done online — I never met or talked to anyone from Pro U — except that, as a new employee, I had to pass a drug test, something that I don’t think I ever had to do back in 1982. That entailed a visit to a clinic on Roscoe Blvd.
So then I had a special badge, and couldn’t enter the facility through the electronic gates but had to pass by a human guard, but otherwise things were mostly the same. I sat in a similar cubicle with a similar PC as before, and I resumed the final changes for the current round of process updates. (This last big effort for Rocketdyne was a consolidation and redrafting of several core software process documents that had been “patched” over the years — a job analogous to the big re-coding projects I did decades before.) It wasn’t a full-time job; I came in late and left early, and got paid (by Pro U) at roughly the same hourly rate I had been earning as a salaried employee (though of course with no benefits). Since I wasn’t a full-time employee and not involved in any decisions the software group might make, there were a lot of meetings I didn’t have to attend.
The first stint as a contractor last about nine months, until March 2014. There was another period of three weeks or so in August and September (to support a CMMI assessment, maybe?). And then nothing for a while. By the end of 2014 we were arranging to move from LA to the Bay Area…
Two full years later in August 2016 I got another call, from my immediate manager Alan P. (My partner and I were strolling through the de Young Museum in Golden Gate Park at the time.) Interested in more contract work? Would be working from home on a laptop. Um, OK. This time I had to drive down to LA, re-enroll in Pro U and get another blood test, and then spent two or three days at the facility with Alan and Mark R updating me on all the SEPG goings-on. I got a work laptop to take home with me, and instructions about logging in over the internet using a VPN, and so on. I managed to find files I’d left on the company server from 2014, and picked where I’d left off. Ironically, I had to take a lot of the process training *myself,* because refreshers were due every two or three years, and I was overdue. I had written some of that training…
So more part-time work for several months, though I see from my records I didn’t ship the laptop *back* until October 2018. I think my assigned tasks were very intermittent, and as I got busier with projects of my own at home, I told Alan it was a good time to retire from the rocket factory for good.



{kind=link}
{kind=link}